
Metadaten als zentrale Rolle im Data Lake und Self-Service-Szenarien
Mit einem Data Lake realisieren Sie eine zentrale Datenplattform für sämtliche Arten von Endbenutzern. Das Ziel ist die Demokratisierung, also eine möglichst umfassende Durchdringung sämtlicher Prozesse und Entscheidungsebenen des Unternehmens mit datengetriebenen Methoden und Anwendungsfällen (vom IT-Spezialist bis zum Fachanwender). Lesen Sie in diesem Beitrag, welche zentrale Rolle Metadaten für eine erfolgreiche Umsetzung des Data Lake und den darauf basierenden Self-Service-Szenarien spielen.
Anforderungen an einen Data Lake
Mit Nutzung eines Data Lake gewinnen organisatorische und technische Regelungsanforderungen (Governance-Anforderungen) an Bedeutung. Einerseits muss eine regel- und gesetzeskonforme Nutzung (Compliance) des Data Lake sichergestellt sein. Andererseits geht es darum, einen effizienten technischen Betrieb des Data Lake zu gewährleisten.

Ein wesentlicher Faktor sind dabei Anforderungen aus der EU-Datenschutz- Grundverordnung (DSGVO), die eine transparente und zweckgebundene Verarbeitung personenbezogener Daten vorschreibt und nachweispflichtig macht. Dies erfordert eine umfassende und aktuell gehaltene Metadatendokumentation über Batch- und Streaming-Komponenten im Data Lake. Datenbereiche mit personenbezogenen Daten müssen dazu inventarisiert werden. Ein praktisches Anwendungsbeispiel sind Anforderungen von Kunden zur Löschung ihrer personenbezogenen Daten. Ein (Standard-)Prozess, der sich mittels entsprechender Metadaten im Data Lake effektiv und problemlos umsetzen lässt.
Ein weiterer Faktor sind Regelungsanforderungen, die sich aus der digitalen Transformation ergeben. Daten sind ein zentraler Wertgegenstand und erfordern ein systematisches Datenqualitätsmanagement sowie organisatorische Verantwortlichkeiten und Prozesse. Es geht insbesondere um unternehmensinterne Regelungen für Dateneigentum und -nutzung. Sämtliche Informationen zur Herkunft, Qualität und organisatorischen Verantwortlichkeit der Daten sind Metadaten im Data Lake, die systematisch verwaltet werden müssen.
Datenredundanzen im Data Lake aufdecken
Die Vielzahl an Datenhaltungssystemen eines Unternehmens bedingt natürlicherweise Datenredundanzen. Diese gilt es in einem Data Lake systematisch zu verwalteten und transparent zu machen, um Inkonsistenzen zu vermeiden beziehungsweise deutlich zu machen und die Speicherkosten zu optimieren.
Darüber hinaus sind für einen wirtschaftlichen Betrieb des Data Lake effiziente Änderungsprozesse bei Modifikationen der zugrundeliegenden Quellsysteme wie Systemkonsolidierungen oder Software-Aktualisierungen wichtig. Diese Änderungen müssen auf Basis von Impact-Informationen (Metadaten) unter anderem im Data Lake nachvollzogen werden, um beispielsweise Transformationsprozesse anzupassen und die Datenbereitstellung im Data Lake aufrecht zu erhalten.
Die notwendige Transparenz über Datenredundanzen sowie Auswirkungen von Quellsystemänderungen basiert auf entsprechenden Metadaten zu Datenbereichen sowie Quellsystemen des Data Lake. Ein ganzheitliches Metadatenmanagement unterstützt die erfolgreiche Umsetzung verschiedenster Governance-Anforderungen im Data Lake.
Self-Service dank Metadaten
Für die Demokratisierung der Data-Lake-Nutzung sind Konzepte und IT-Werkzeuge für Self-Service-Szenarien besonders relevant. Das Ziel besteht darin, Fachanwendern die Datenaufbereitung und -analyse mit einfach nutzbaren IT-Werkzeugen zu ermöglichen.
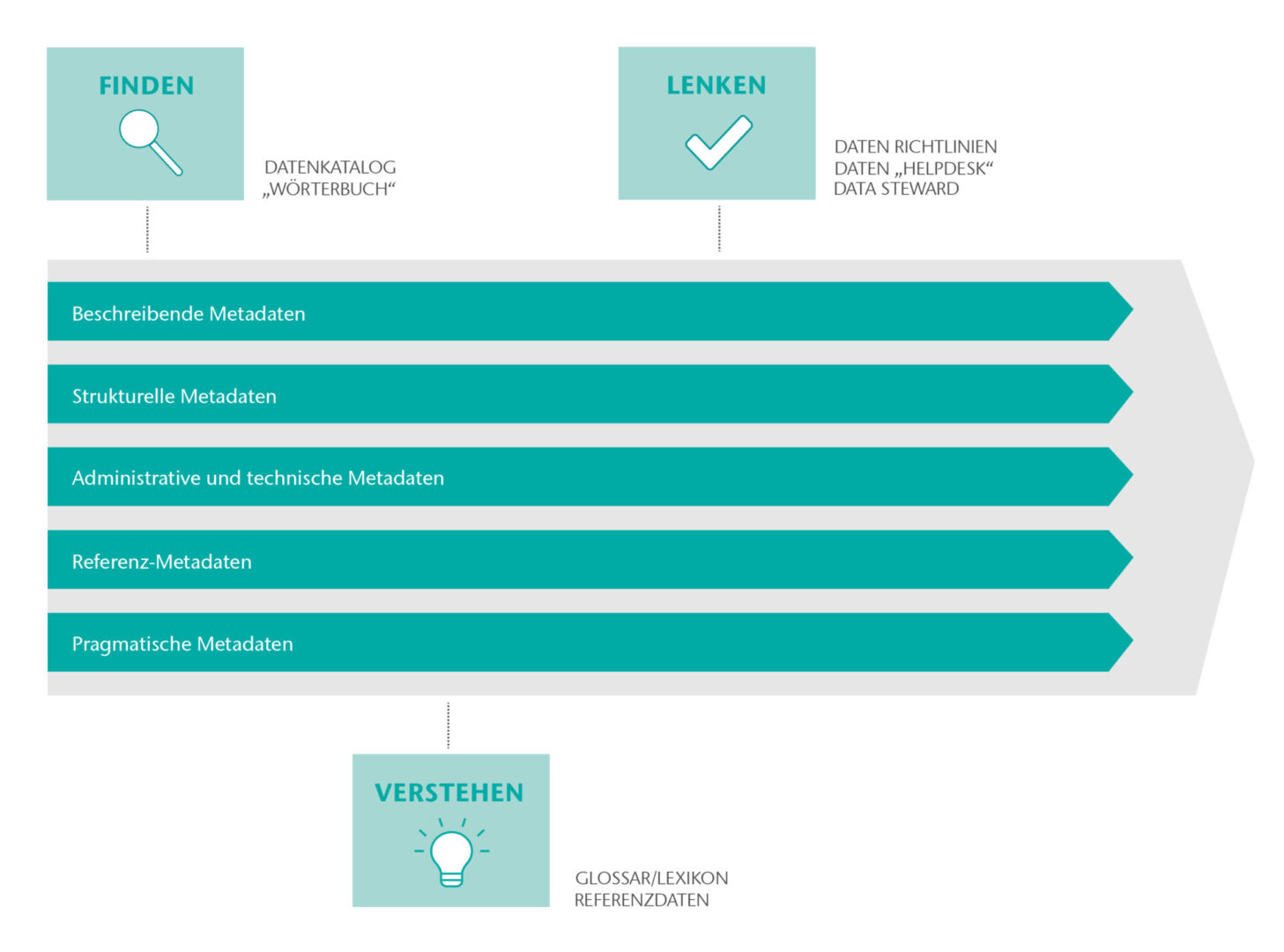
Es gibt unter anderem beschreibende, strukturelle, administrative, pragmatische sowie Referenz-Metadaten.
Eine umfassende Unterstützung durch IT-Experten ist dabei nicht erforderlich. Metadaten spielen eine zentrale Rolle bei der Umsetzung von Self-Service-Szenarien. Hierbei geht es insbesondere um:
- die Unterstützung der „Daten-Entdeckung“ (Data Discovery) zur Identifikation relevanter Datenbereiche im Data Lake, um sämtliche für eine spezifische Fragestellung relevanten Daten zu selektieren
- die Beurteilung der Datenherkunft (Data Lineage) und Datenqualität (Data Quality) als kritischer Erfolgsfaktor, um eine zuverlässige und vertrauenswürdige Nutzung der Daten zu ermöglichen
- die Daten- und Ergebnisinterpretation durch Fachanwender (Bedeutung betriebswirtschaftlicher Kennzahlen, die Abgrenzung von Fachbegriffen im Rahmen von Glossaren oder die Struktur von Aggregationshierarchien)
Das Metadatenmanagement in dem Szenario „Unterstützung von Self-Service-Informationsbeschaffung“ beinhaltet beides:
- eine ganzheitliche Verwaltung und Bereitstellung der Metadaten für Fachanwender entlang des gesamten Datenaufbereitungs- und Analyseprozesses
- das Erfassen und „Wiederverwertbar-Machen“ zusätzlicher Metadaten/Arbeitsergebnisse durch Fachanwender
Um mit der Vielzahl von Daten und Datenformaten in Data Lakes und darauf aufbauenden Self-Service-Szenarien effizient und regelkonform umgehen zu können, sind sorgfältig gepflegte und stringent verwaltete Metadaten also unerlässlich. Ein intelligentes Metadatenmanagement unterstützt Sie dabei, die benötigte Transparenz und Handhabbarkeit sicherzustellen und damit die Mehrwerte einer umfassenden Datenhaltung, Datennutzung und Datenauswertung im Sinne einer ganzheitlichen Data Intelligence nutzbar zu machen.
Über den Autor

Hanjörg Poppe ist Diplom Informatiker und geht seiner Begeisterung für IT seit mehr als 25 Jahren bei CONET nach. Als Senior Consultant bei der CONET Business Consultants GmbH liegen seine Schwerpunkte auf den Themen Business Intelligence und Data Intelligence.




