
Data-Centric AI: Mit Datenpräzision die KI-Effizienz steigern
In der sich schnell entwickelnden Welt der Künstlichen Intelligenz (KI) und mit der rasanten Zunahme an Informationen, die durch die digitale Transformation generiert werden, rückt die zentrale Bedeutung von Daten für innovative IT-Lösungen immer stärker in den Fokus.
Data-Centric AI (DCAI) stellt einen wegweisenden Ansatz in der KI dar, indem es die Qualität und Relevanz von Daten in den Mittelpunkt rückt, um Modelle des maschinellen Lernens und die Performance von Systemen zu optimieren. Dieser bedeutende Paradigmenwechsel findet auch im Bereich der Computer Vision seine Anwendung. Um bestmögliche Lösungen zu schaffen, setzt das CONET-Data-Analytics und -AI-Team auf die Integration von DCAI in Computer-Vision-Projekten.
Im folgenden Blog-Artikel erläutern wir das Konzept von DCAI und gehen insbesondere darauf ein, wie es sich vom klassischen, modellzentrierten Entwicklungsprozess für KI-Lösungen unterscheidet und welche Auswirkungen dies auf den Bereich der Computer Vision hat. Abschließend stellen wir eine standardisierte DCAI-Pipeline vor.
Inhaltsverzeichnis
Was ist Data-Centric AI?
Data-Centric AI ist ein Ansatz in der Künstlichen Intelligenz und dem Machine Learning (ML), bei dem der Schwerpunkt auf der Verbesserung und Optimierung der Datenqualität liegt. DCAI konzentriert sich darauf, die Qualität, Relevanz und Sauberkeit der Daten zu verbessern, die man für das Training von KI-Modellen verwendet. Im Gegensatz zu modellzentrierten Ansätzen, die auf die Entwicklung komplexerer Algorithmen abzielen, sieht dieser Ansatz die Daten selbst als Schlüsselfaktor für die Leistung der KI. Data-Centric AI ermöglicht effizientere und präzisere KI-Systeme, indem es die Grundlage verbessert, auf der diese Systeme aufbauen.
Warum Data-Centric AI in der Computer Vision?
Auch in Computer-Vision-Projekten spielt die Datenqualität eine entscheidende Rolle. Ein diversifizierter und sorgfältig aufbereiteter Datensatz befähigt Modelle dazu, effektiv zu generalisieren und eine umfangreiche Vielfalt an Mustern zu identifizieren. Ein datenzentrierter Ansatz rückt daher in den Mittelpunkt, um aktiv Bias in Computer-Vision-Systemen entgegenzuwirken. Unter Bias versteht man die Neigung zu verzerrten oder nicht repräsentativen Inhalten, die die Unvoreingenommenheit von maschinellem Lernen beeinträchtigen können. Dies kann zu algorithmischer Diskriminierung führen, bei der Systeme in bestimmten Anwendungen, wie der Gesichtserkennung, Fehler oder Ungerechtigkeiten aufzeigen. Dies erfolgt insbesondere, wenn die Trainingsdaten nicht divers und umfassend sind. Forschungen, beispielsweise von der Gruppe Fairness and Accountability in Machine Learning (FAT/ML) bei Microsoft Research, unterstreichen die Bedeutung der Bekämpfung von Bias in visuellen Daten für faire und ethische KI-Praktiken. Durch eingehende Datenanalysen und sorgfältige Datenaufbereitung lassen sich Verzerrungen erkennen und korrigieren. So wird die Fairness von KI-Anwendungen gegenüber verschiedenen Bevölkerungsgruppen gewährleistet.
Was genau kann der DCAI-Ansatz in Computer-Vision-Projekten optimieren?
- Verbesserung der Modellgenauigkeit: DCAI-Techniken sind darauf ausgerichtet, die Datenqualität zu verbessern, indem sie für einen Datensatz sorgen, der eine breite Vielfalt an Bildern umfasst. Diese Bilder decken unterschiedliche Beleuchtungsverhältnisse und Perspektiven ab. Durch die Diversifikation wird es den Modellen ermöglicht, Metadaten genauer zu interpretieren und komplexe Muster mit gesteigerter Genauigkeit zu erkennen, was ihre Fähigkeit zur Generalisierung erheblich verbessert.
- Identifizierung und Reduzierung von Bias: Die Auswahl von Daten für einen (visuellen) Datensatz kann zu Verzerrungen führen, beispielsweise, wenn bestimmte Unternehmensprozesse oder gesellschaftliche Gruppen in den Daten nicht ausreichend repräsentiert sind. DCAI kann genutzt werden, um solche Verzerrungen zu identifizieren und abzumildern.
- Optimierte Modellrobustheit: Eine gezielte Optimierung der Datenaufbereitung erhöht die Leistungsfähigkeit dieser Modelle. In realen Einsatzgebieten sind sie dadurch effektiver und bewältigen sowohl Datenvielfalt als auch dynamische Veränderungen besser.
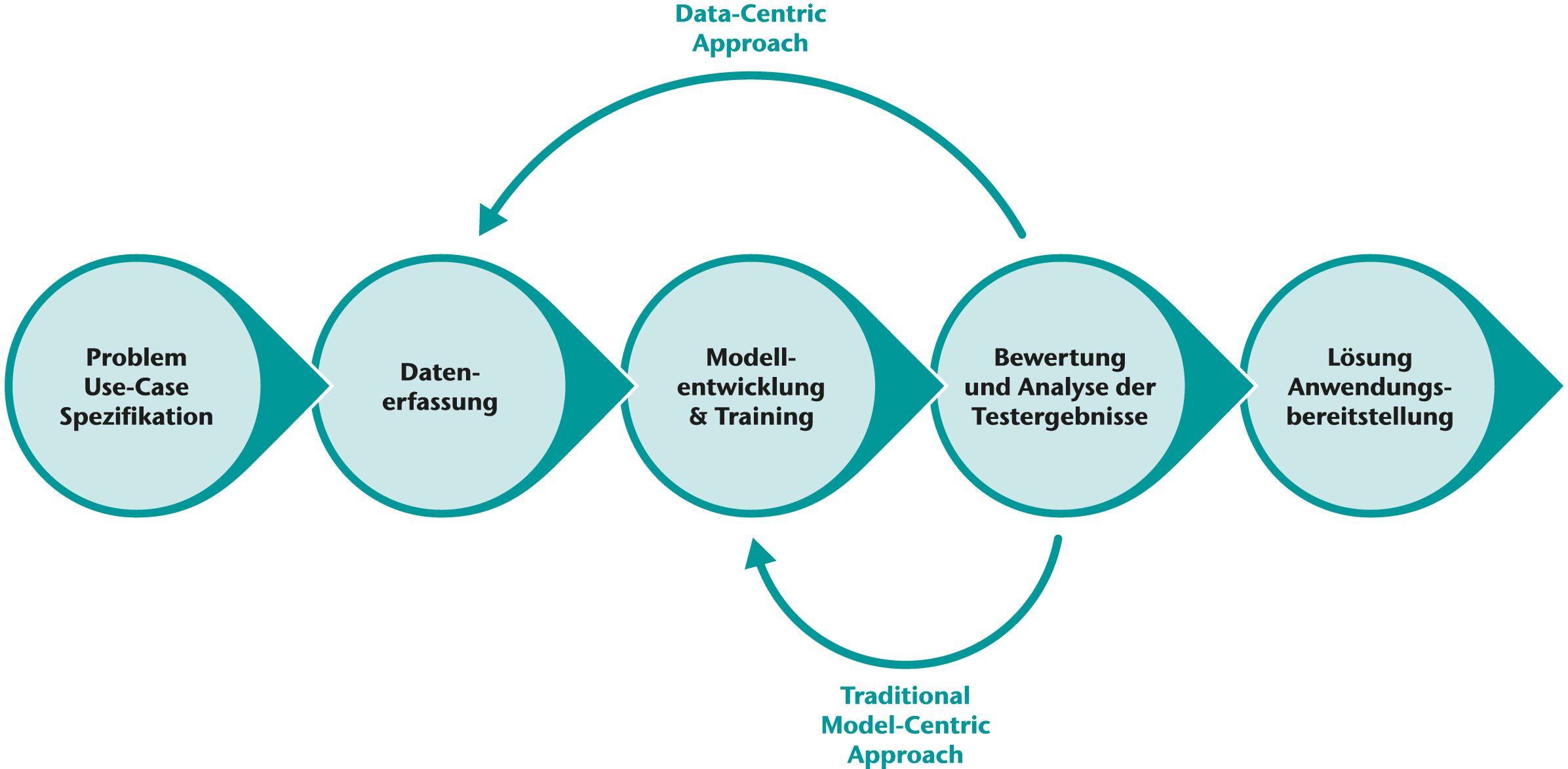
Ansätze zur Implementierung von Data-Centric AI in der Computer Vision
Obwohl die Datenqualität auch in einem modellzentrischen KI-Entwicklungsansatz wichtig ist, nimmt sie bei der Entwicklung nach dem DCAI-Prinzip eine zentrale Rolle ein. Im Folgenden stellen wir Methoden vor, die typischerweise in der Entwicklung mit einem DCAI-Ansatz zur Anwendung kommen.
- Fehlererkennung und -korrektur: Typische Fehler in Computer-Vision-Datensätzen sind falsch oder ungenau annotierte Bilder. Um diese zu identifizieren und zu bereinigen, werden Methoden wie Cross-Validierung, Überprüfung der Konsistenz oder der Einsatz vortrainierter Modelle zur Fehlererkennung verwendet. Diese Verfahren tragen entscheidend zur Steigerung der Trainingsdatenqualität bei.
- Data Augmentation: Datenaugmentierung, auch Datenerweiterung genannt, umfasst die Anwendung diverser Transformationstechniken wie Drehung, Spiegelung oder Helligkeitsanpassung auf visuelle Daten. Diese Verfahren generieren zusätzliche Varianz im Datensatz. Mit Datenaugmentierung wird in Computer-Vision-Projekten der Trainingsdatensatz um eine vielfältigere und umfangreichere Auswahl an Szenarien erweitert und so die Generalisierungsfähigkeit der Modelle gesteigert.
- Active Learning: Beim Active Learning verbessert die Auswahl der informativsten Datenpunkte die Gesamtleistung des Modells. Als besonders informativ betrachtet diese Methode Daten, bei denen das Modell unsicher ist. Häufig genutzte Active-Learning-Algorithmen sind beispielsweise Selective Sampling, Iterative-Refinement, Uncertainty Sampling und Query by Committee. Weitere detaillierte Informationen zum Prozess des Active Learning finden Sie in diesem Blog-Beitrag.
- Curriculum Learning: Curriculum Learning basiert auf dem Prinzip, Trainingsdaten nach ihrer Lernschwierigkeit zu sortieren – beginnend mit einfachen bis hin zu komplexen Aufgaben. Diese Methode ähnelt dem menschlichen Lernprozess, bei dem ein schrittweises Vorgehen bei komplizierteren Aufgaben Anwendung findet. Durch diese Strategie lässt sich die Effizienz des Lernprozesses steigern.
- Feature Engineering und -Auswahl: Im Kontext von Computer Vision bezieht sich Feature Engineering auf das Identifizieren und Verarbeiten signifikanter Merkmale aus Bild- oder Videodaten, um die Leistung von KI-Modellen zu optimieren. Durch Techniken wie das Histogram of Oriented Gradients (HOG) oder Convolutional Neural Networks (CNNs) werden relevante Attribute extrahiert. Diese Schritte sind entscheidend, um die Dimensionalität der Daten zu verringern und damit das Training von KI-Modellen effizienter zu gestalten.
Eine typische Data-Centric-AI-Pipeline
Die Integration von Data-Centric AI in Computer-Vision-Projekte folgt einem klaren Prozess. Zunächst werden Daten gesammelt und sorgfältig ausgewählt, um realistische Szenarien abzudecken. Darauffolgend werden die Daten analysiert und bereinigt und so für das maschinelle Lernen vorbereitet. Der nächste Schritt ist das Training eines Grundmodells mit dem bereinigten Datensatz – gefolgt von Tests und Bewertungen. Eine kontinuierliche Überwachung der Datenqualität ist essentiell, um die Integrität des KI-Modells zu gewährleisten und es an neue Gegebenheiten oder Daten anzupassen. Ein datenzentrierter KI-Ansatz optimiert den gesamten Entwicklungsprozess und gestaltet ihn effizient.
Mit CONET die Zukunft der Computer Vision gestalten
Bei CONET legen wir Wert auf das datenzentrierte Paradigma. Wir treiben Innovationen im Bereich der Computer Vision voran – unterstützt durch den Einsatz modernster Technologien. Wir laden Sie ein, gemeinsam mit uns das Potential der datenzentrierten Künstlichen Intelligenz auszuschöpfen. Gemeinsam können wir eine Zukunft gestalten, in der Maschinen die Welt präzise verstehen.
War dieser Artikel hilfreich für Sie? Oder haben Sie weiterführende Fragen zur Computer Vision? Schreiben Sie uns einen Kommentar oder rufen Sie uns gerne an.
Über den Autor

Ferdousi Rahman ist Junior Consultant bei der CONET Solutions GmbH im Team Data Analytics und AI. Sie hat an Projekten in den Bereichen Datenanalyse, Visualisierung und maschinelles Lernen mitgewirkt und dabei innovative KI-Technologien aus dem Bereich der Datenwissenschaft integriert.



