
Planung einer KI-Infrastruktur – eine kleine Reise
Neue Technologien wie künstliche Intelligenz (KI) gewinnen in Zeiten der Digitalisierung rasant an Bedeutung. Doch wie kann der Einsatz einer KI-Infrastruktur erfolgreich geplant werden? In unserem Blog-Beitrag schildern wir notwendige Planungsschritte.
Um den infrastrukturellen Bedarf für eine KI-Lösung ermitteln zu können, ist eine Abstimmung mit den jeweiligen Entscheidungsträgern der Organisation aus den Bereichen Datenschutz und Betrieb notwendig. Die Gestaltung der Infrastruktur hängt dabei stark von der jeweiligen Anwendung ab. „The more the merrier“ („viel hilft viel“) gilt hier nicht, da gerade die Beschaffung von GPU-Clustern sehr kostenintensiv ausfallen kann. Sind diese dann mit der vorhandenen Infrastruktur nicht kompatibel und ist der Server-Raum nicht ausreichend gekühlt, dann ist das Ziel verfehlt.
„Herr Schaffner ich brauche ein Ticket“ – Der Datenschutzbeauftragte
Bevor die Planung des infrastrukturellen Bedarfs für KI-Anwendungen beginnt, sollte der Datenschutzbeauftragte konsultiert werden. Cloud-Anbieter wie Amazon Web Series (AWS) oder Microsoft Azure bieten ein sehr hohes Sicherheitsniveau. Allerdings kann ein Verlust von sensiblen Daten einen derart großen Schaden anrichten, dass eine Auslagerung der Daten in die Cloud nicht vertretbar ist. Zu beachten ist außerdem, dass die Daten unter Umständen nicht auf Servern in Deutschland gehostet werden. Dieser Punkt muss rechtlich abgesichert sein und sollte in jedem Fall mit der Datenschutz-Grundverordnung (DSGVO) in Einklang stehen.
„Wo soll die Reise hingehen?“ – Ausfahrt Cloud
GPU-Power muss nicht mehr zwingend inhouse bereitgestellt, sondern kann bei einem Cloud-Anbieter gebucht werden.
Der Vergleich potenzieller Cloud-Anbieter macht auf unterschiedliche Machine-Learning-Angebote aufmerksam und ist aufgrund der zahlreichen Optionen nicht trivial. Wartungs-Services (Support) werden durch den Cloud-Anbieter bereitgestellt und sind in der Regel kostengünstiger als ein Inhouse Support.
Infrastruktur und Rechenleistung aus der Cloud zu beziehen, kann finanzielle Vorteile mit sich bringen, wenn ein „pay per use“-Preismodell genutzt wird. Bei einem solchen Modell wird nur die Rechenleistung bezahlt, die tatsächlich verwendet wurde. Die größte Auslastung der Hardware entsteht während des Trainings. Für den produktiven Einsatz (Inferenz) hingegen wird in der Regel weniger Rechenleistung benötigt.
Es besteht die Möglichkeit eines hybriden Ansatzes, welcher aus dem Training in der Cloud und dem Hosting der Anwendung im eigenen Rechenzentrum besteht. Zudem kann für das Training nur das vortrainierte Netz über eine API des Cloud-Anbieters genutzt werden. Wenn der Anwendungsfall nicht zu spezifisch ist, kann außerdem ein „Machine Learning as a Service (MLaaS)“-Angebot sinnvoll sein. Die großen Cloud-Anbieter bieten mit MLaaS schon fertige Produkte an (z. B.: Azure Cognitive Services). Ein weiterer Nutzen des Trainings in der Cloud liegt in der Bereitstellung weiterer Tools wie z. B. Annotations-Assistenten zur Beschriftung des Datensatzes.
Ausfahrt Inhouse
Wird eine Inhouse-Lösung bevorzugt, sollte mit dem Betrieb gesprochen werden. Dabei ist die Bereitschaft erforderlich, eine Infrastruktur für KI-Anwendungen zur Verfügung zu stellen. Sollten bereits GPUs vorhanden sein, so kann geprüft werden, ob diese voll ausgelastet sind oder ob die bestehende Hardware problemlos durch GPUs erweitert werden kann. Teuer sind hierbei nicht unbedingt die Prozessoren an sich, sondern ein ausreichend großer Raum, das Verlegen der Netzwerkkabel und die Zeit, die für den Aufbau benötigt wird. Aus unserer Sicht ist davon abzuraten, eine zweite Infrastruktur speziell für KI-Anwendungen aufzubauen. Sollte dies jedoch unvermeidbar sein, so ist darauf zu achten, dass die KI-Software zur KI-Hardware passt. Diverse Anbieter bieten dies als Kombi-Paket an (z. B. NVIDIA DGX). Ist es nicht notwendig oder erwünscht, dass der KI-Rechner am Netzwerk angeschlossen ist und die Datenmenge überschaubar, ist auch ein leistungsstarker Stand-Alone-PC ausreichend, um ein neuronales Netz zu trainieren. Drittanbieter-Software-Hersteller für z. B. das kollaborative Labeln von Daten bieten oftmals sowohl den Inhouse-Betrieb als auch eine Cloud-Lösung an. Für letztere ist der Support häufig einfacher und die Kosten somit geringer.
„Bitte aussteigen“ – API-Infrastruktur
Für den Zugriff auf die KI-Anwendung ist eine REST-API zu empfehlen. Es bieten sich für die Entwicklung von REST-APIs eine Reihe bestehender Frameworks an. Dabei hat sich Docker für die Bereitstellung von Containern etabliert. Kombinierte Systeme (z. B. NVIDIA DGX, s.o.) beinhalten bereits eine Docker-Engine (siehe Abbildung 1). Wird die Hardware ohne Software-Stack beschafft, müssen die passenden Treiber für die Hardware und die ML/DL-Frameworks manuell auf einem Betriebssystem installiert werden. ML-Komponenten können unabhängig von anderen Software-Komponenten entwickelt werden, wenn Standarddatenschnittstellen und Standardausgabeformate (z. B. ONNX) verwendet werden.
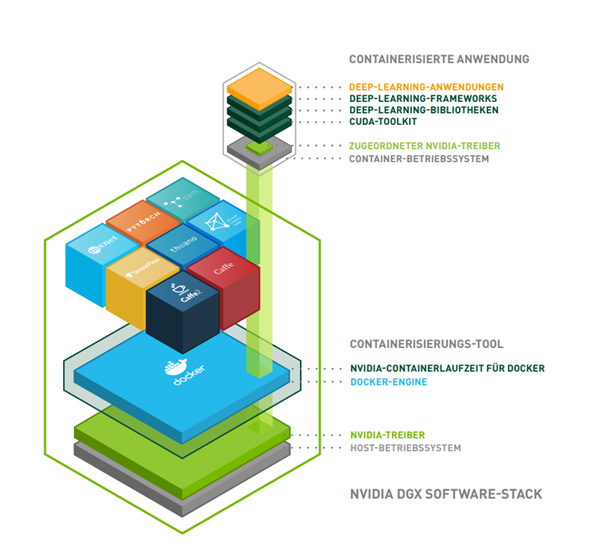
Abbildung 1: Kombinierte Systeme wie das NVIDIA DGX Software-Stack beinhalten bereits eine Docker-Engine. (Quelle: NVIDIA)
Soll die KI-Anwendung nicht autark, sondern als Teil einer Software-Lösung verwendet werden, so sind passende Schnittstellen vorzusehen. Dabei sollten sich Verantwortliche darüber Gedanken machen, an welcher Stelle die Daten an das Backend (also an das KI-Modell) geschickt werden und wo diese in welcher Form in der Hauptanwendung sichtbar gemacht werden. Dies kann von einem textuellen Feedback bis hin zu einem Dashboard reichen. Sind nun alle involvierten Entscheidungsträger zufrieden, ist das Ziel der kleinen Reise für den Einsatz einer KI-Infrastruktur erreicht.
Über den Autor

Johann Martens arbeitet seit zwei Jahren bei CONET und ist als Senior Developer im Bereich Software Engineering tätig. Zu seinen Kernthemen gehören Java-Geschäftsanwendungen und Machine Learning.




Super geschriebener und informativer Artikel :-). In diesen Blog werde ich mich noch richtig einlesen