
SAP HANA – Erfahrungen mit der In-Memory-Datenbank, Teil 2: SELECT- und UPDATE-Operationen
Im ersten Teil dieser Blogreihe haben wir gesehen, dass SAP HANA bei Insert-Operationen einen deutlichen Geschwindigkeitsvorteil gegenüber einer traditionellen SQL-Datenbank besitzen kann. Die Vermutung lag nahe, dass dies an einem extrem schnellen Lesevorgang im Rahmen einer INSERT INTO … SELECT FROM – Anweisung liegt.
Dies wollen wir im vorliegenden zweiten Teil der Blogreihe untersuchen.
Zur Erinnerung: wir haben eine Tabelle „Kennzeichen“ mit 7.020.000 Datensätzen angelegt, die folgende Spalten besitzt:

Auf dieser Tabelle sollen nun verschiedene Select-Operationen ausgeführt werden, um die Performance der Operationen mit einer traditionellen SQL-Datenbank zu vergleichen.
Wie im ersten Teil werden auch hier die SQL-Anweisungen über die SQL Console des SAP HANA Studios über einen DB-Tunnel auf die SAP HANA Cloud abgesetzt.
SELECT-Anweisungen
Zunächst wollen wir einen Überblick über die Verteilung der Kennzeichen innerhalb des Landkreises erhalten:
![]()
Diese Abfrage liefert folgendes Ergebnis:
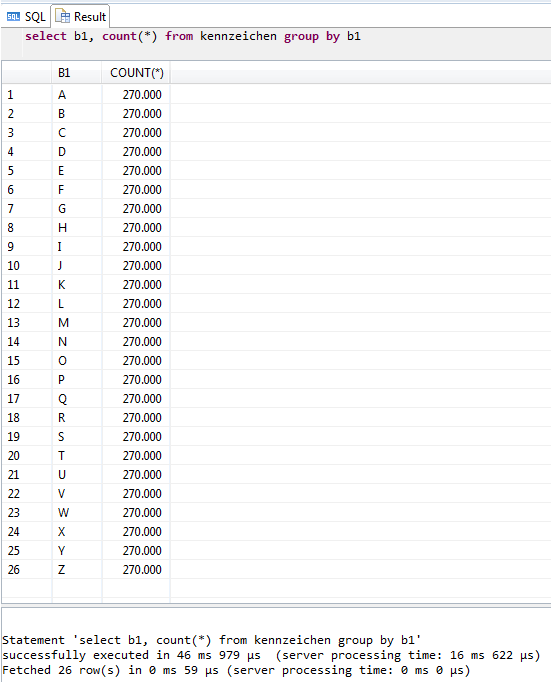
Die Ergebnisse zu den einzelnen Buchstaben sind nach den Insert-Operationen aus dem ersten Teil plausibel: 26 Buchstaben und die Leerstelle wurden für das Feld „b2“ verwendet und für jeden Eintrag in „b2“ wurden 10.000 Zahlenkombinationen in den Feldern „z1“ bis „z4“ verwendet. Somit ergeben sich je Buchstabe im Feld „b1“ 270.000 Datensätze.
Für die Betrachtung der Datenbank-Performance ist die „server processing time“ in der obigen Abbildung relevant. Diese besagt, dass alle 7.020.000 Datensätze unserer Tabelle „Kennzeichen“ in 16 ms ausgewertet wurden.
Dieser Wert ist beeindruckend. Um ihn aber richtig einordnen zu können, soll folgende Erläuterung dienen: eine ähnliche Abfrage über alle Daten der Einwohner der Bundesrepublik Deutschland (ca. 80 Millionen Datensätze) würde ihr Ergebnis bereits nach 0,2 Sekunden liefern. Wirklich beeindruckend – oder?
Durch die Organisation der Tabelle „Kennzeichen“ als spaltenorientierte Tabelle sind diese Zeitangaben für die obige SQL-Abfrage unabhängig von der Breite der Tabelle. Dies bedeutet, dass auch viele zusätzliche Felder in der Tabelle die Performance dieser Abfrage nicht beeinflussen werden. In SAP HANA werden in spaltenorientierten Tabellen nur die tatsächlich angesprochenen Felder (im obigen Beispiel das Feld „b1“) gelesen und ausgewertet.
Die Performance der SELECT-Operationen wollen wir noch an weiteren Beispielen überprüfen.
Zunächst eine Auswertung mit einer weiteren Gliederungsebene:

Auch hier haben wir eine Antwortzeit in derselben Größenordnung wie oben.
Der nächste Versuch geht auf die detailliertere Auswertung weniger Spalten:
![]()
Diese Auswertung liefert folgendes Ergebnis:
![]()
Also: in 3 ms aus 7.020.000 Datensätzen die 10 gesuchten herausgefiltert und die gewünschten Feldinhalte zu diesen Datensätzen zurückgeliefert.
Zum Abschluss dieser Reihe noch eine „Todsünde“ für spaltenorientierte Tabellen: SELECT * FROM <tabelle>. Dadurch dass die Werte für ein Feld einer Tabelle zusammen abgespeichert werden, kann eine Auswertung über ein Feld leicht und schnell erfolgen. In spaltenorientierten Tabellen ist dagegen das „Zusammensuchen“ aller Werte zu einem Datensatz eine relativ zeitaufwändige Aktion. Deshalb sollten nur die Felder in der Select-Liste angegeben werden, die auch tatsächlich benötigt werden.
Wir suchen uns nun alle Datenwerte zu 1.000 Datensätzen aus unserer Tabelle über folgende SQL-Anweisung:

Dass SAP HANA auch diese Operation erfolgreich und sehr performant erledigt, zeigt die Auswertung der SQL-Anweisung:

Vergleich zu SQL
Bevor wir uns die Performance von UPDATE-Operationen ansehen wollen, sollen die obigen Ergebnisse zunächst mit den Werten für eine traditionelle SQL-Datenbank verglichen werden.
Die Werte hängen sehr stark von der Definition zusätzlicher Indizes über die selektierten Datenfelder ab. Durch zusätzliche Indizes kann die Performance deutlich gesteigert werden, allerdings sind hier auch Grenzen gesetzt: nicht über jedes Feld kann sinnvollerweise ein Index definiert werden, weil dadurch viel zusätzlicher Plattenplatz beansprucht wird und die Performance von INSERT- und UPDATE-Operationen spürbar sinkt. Die nachträgliche Erzeugung der Indizes über die gefüllte Tabelle nahm mehr als 7 Minuten in Anspruch.
In der nachfolgenden Tabelle werden die Werte in Spalte 2 ohne zusätzliche Indizes und zum anderen mit zusätzlichen Indizes über die Felder „b1“ und „b2“ dargestellt.
| Statement | Dauer SQL-Datenbank | SQL-Datenbank mit Indizes | Dauer HANA |
| select b1, count(*) from kennzeichen group by b1 | 6.400 ms | 500 ms | 16 ms |
| select b1, b2, count(*) from kennzeichen group by b1, b2 | 7.500 ms | 7.500 ms | 19 ms |
| select b1, b2, z1, z2, z3, z4, name from kennzeichen where lkr=’AAA’ and b1=’A’ and b2=’A’ and z1=’1′ and z2=’2′ and z3=’3′ | 6.000 ms | 70 ms | 3 ms |
| select * from kennzeichen where lkr=’AAA’ and b1=’Z’ and b2=’ ‘ and z1=’9′ | 6.500 ms | 100 ms | 3 ms |
Aus dieser Gegenüberstellung lassen sich Geschwindigkeitsvorteile von HANA gegenüber einer traditionellen SQL-Datenbank im Verhältnis zwischen 1:20 und 1:2000 herauslesen.
Nimmt man ein Verhältnis von 1:1000 an (das für nicht durch Indizes optimierte Tabellen durchaus realistisch ist), dann kann man dies z.B. an einem bestehenden Report veranschaulichen: wenn dieser Report heute in einer traditionellen SQL-Datenbank etwa 17 Minuten zur Ergebnisermittlung benötigt, dann würde er diese Ergebnisse in SAP HANA innerhalb von 1 Sekunde liefern. Wow !!
Selbst ein Verhältnis von 1:200 bedeutet, dass man auf Ergebnisse nicht mehr drei Minuten warten muss, sondern diese sofort zur Verfügung stehen!
UPDATE – Anweisungen
Im nächsten Schritt wollen wir uns noch die Performance von UPDATE-Operationen unter HANA ansehen.
Dazu werden wir Änderungen an unterschiedlichen Mengen von Datensätzen durchführen und die Ergebnisse mit denen in einer traditionellen SQL-Datenbank vergleichen.

Dieses Statement selektiert aus der gesamten Datenmenge 100 Datensätze und ändert in diesen ein Feld ab. Hierfür benötigt HANA etwa 10 ms.


Dieses Statement selektiert aus der gesamten Datenmenge 10.000 Datensätze und ändert in diesen ein Feld ab. Hierfür benötigt HANA etwa 12 ms.
![]()
![]()
Vergleich zu SQL
In der nachfolgenden Tabelle werden die Werte für die obigen UPDATE-Statements in einer traditionellen SQL-Datenbank dargestellt.
| Statement | Dauer SQL-Datenbank | Dauer HANA |
| update kennzeichen set status=’R’ where b1=’A’ and b2=’B’ and z1=’1′ and z2=’2′ |
5.700 ms | 10 ms |
| update kennzeichen set status=’R’ where b1=’A’ and b2=’C’ |
5.900 ms | 12 ms |
| update kennzeichen set status=’R’ | 10.000 ms | 6.300 ms |
Vor allem bei den kleineren Datenmengen kommt der schnelle Selektionsmechanismus von SAP HANA wieder zum Tragen. In diesen Fällen ist das Ändern von Datensätzen in SAP HANA wieder deutlich schneller.
Der Unterschied bei einer Änderung der gesamten Datenmenge ist wiederum deutlich geringer.
Fazit Teil 2
Im zweiten Teil der Blog-Reihe haben wir uns vor allem mit der Geschwindigkeit von SELECT-Statements beschäftigt und gesehen, dass hierbei ganz erhebliche Geschwindigkeitsvorteile für SAP HANA festgestellt wurden.
Auch bei UPDATE-Statements liegt SAP HANA teilweise deutlich vor einer traditionellen SQL-Datenbank.
Im dritten Teil wollen wir grundsätzliche Überlegungen zur Bedeutung und zur technischen Realisierung von SAP HANA darstellen.
Über den Autor

Rolf Gadorosi leitet bei der CONET Business Consultants GmbH die Business Unit SAP NetWeaver Development & Administration. In dieser Funktion fungiert er auch als organisatorischer und technischer Projektleiter und System Architect im Schwerpunkt mit Konzeption, Analyse, Design, Realisierung und Einführung von Individuallösungen und Erweiterungen auf Basis der SAP-Produktpalette.




SAP Hana bietet mit der sehr guten Datenbank-Funktionalität eine perfekte Anbindung mit SAP Business One mit. Gerade die Select Funktionen sind da für ERP KMU Systeme sehr nützlich. Ich persönliche habe auch schon gute Ergebnisse mit der relationalen Algebra in Verbindung mit SAP B1 gemacht. (: